TCA 2.1 What's new - Kubernetes Cluster Diagnosis
Telco Cloud Automation 2.1 introduced a new feature to be able to perform better health checks for deployed Kubernetes clusters. This post will explore that functionality.
The diagnosis can be run against management clusters, workload clusters or specific nodepools. When going into the details of each of those objects you will find a Diagnosis tab like in the picture below.
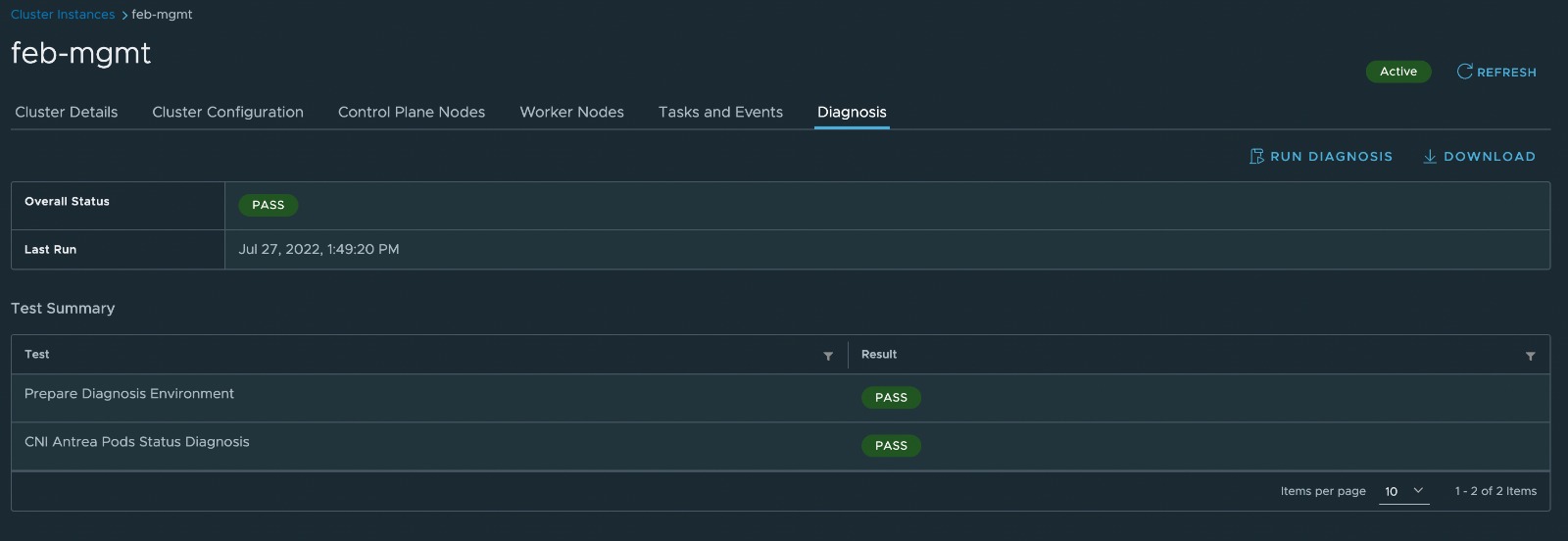
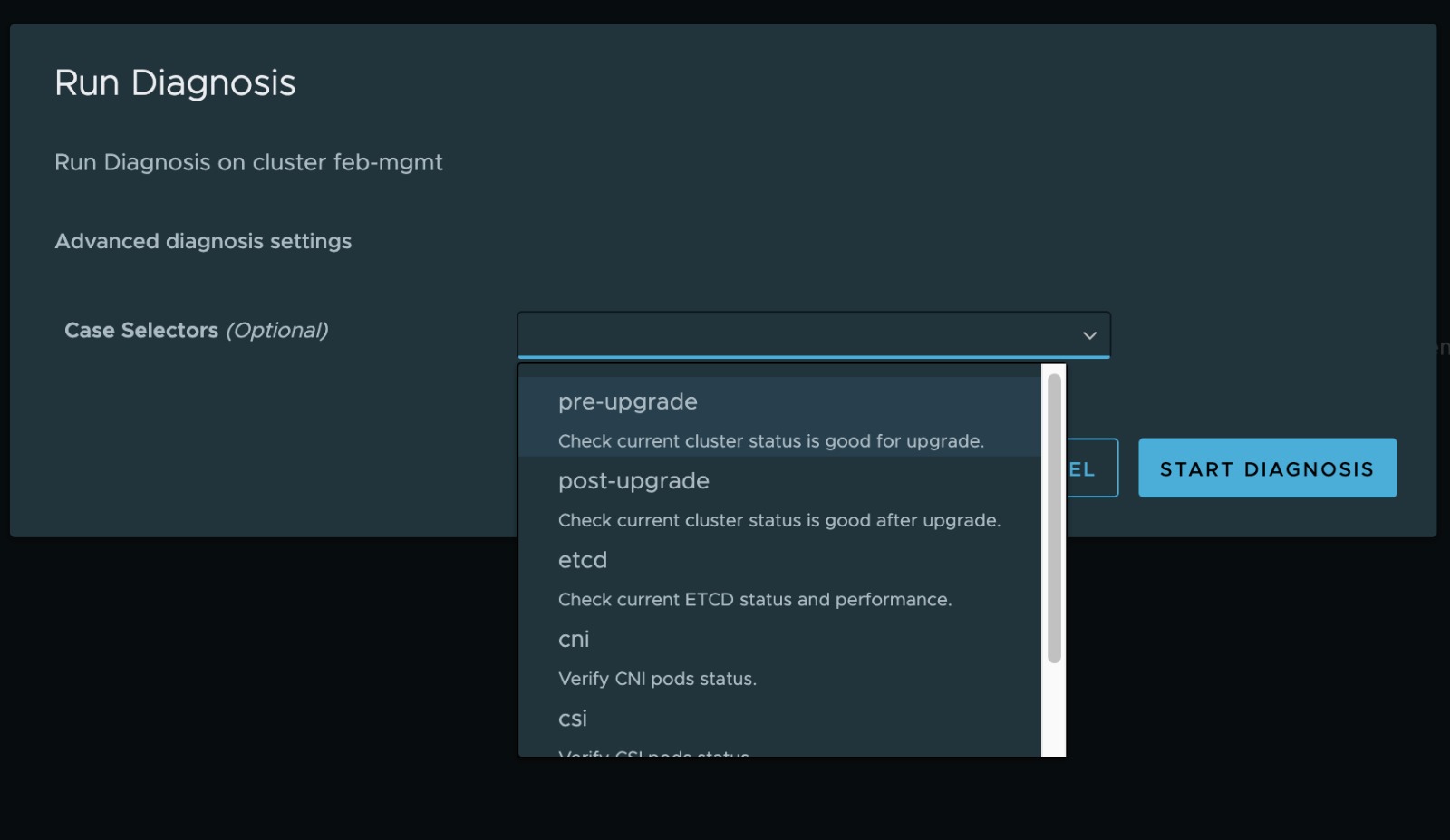
When you first run this you obviously would not have results listed, but still have the button to "Run Diagnosis". When that button is clicked a new wizard pops up which lets you choose if you only want to run a subset of tests (you can simply multi-select by clicking on each of the options you want) or if you leave the field blank (it does read optional) all of the tests at once as shown in the figure below.
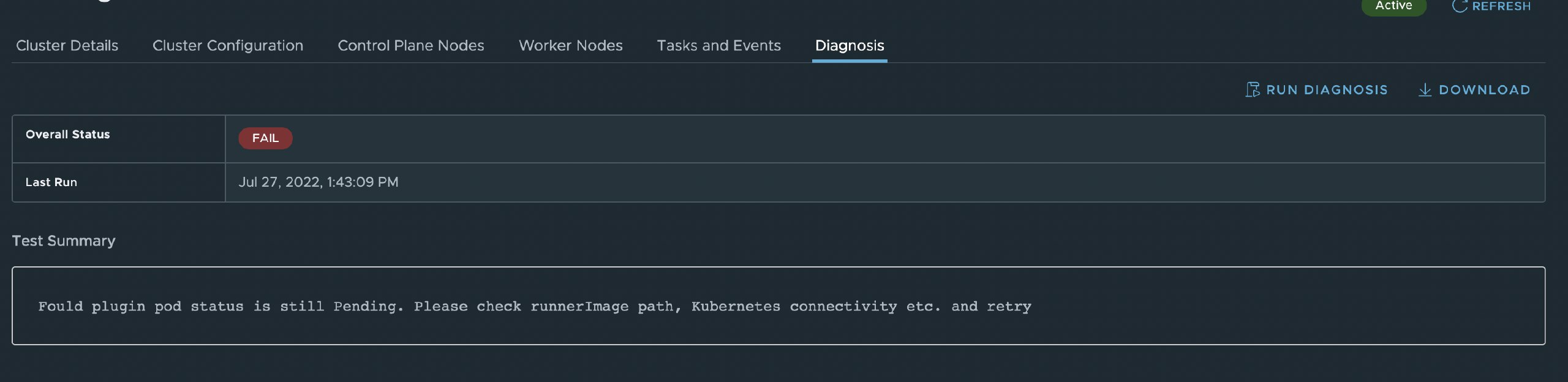
The diagnosis itself will be run through a small helper pod which gets downloaded, the default timeout for this is 60 seconds, depending on the connection to the repository the first run may error out if by that timeout the pod is not fully downloaded or up and running as shown in the picture below. Simply repeat the run and everything should just work fine though.
Once the run completes you will see a summary of the run as well as the conducted tests with their respective pass or failure status.
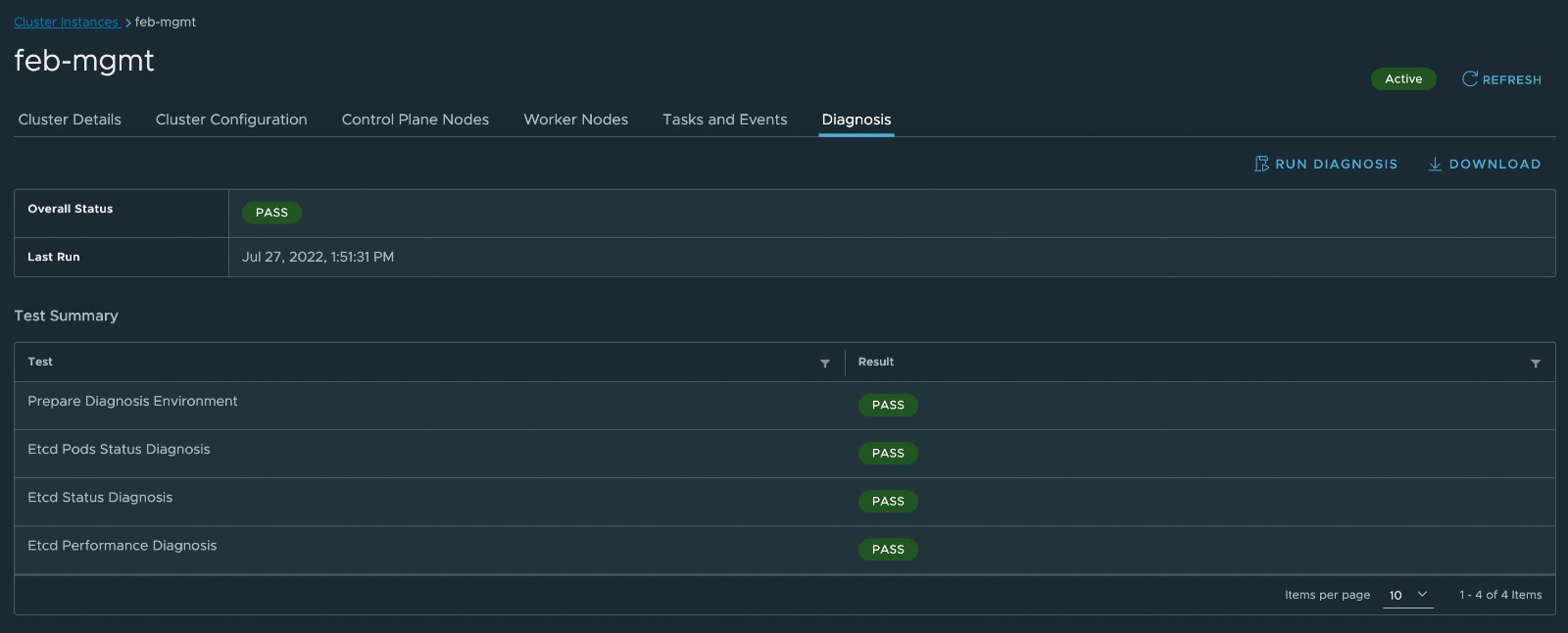
If a test fails the overall status and the respective test will be marked as fail.
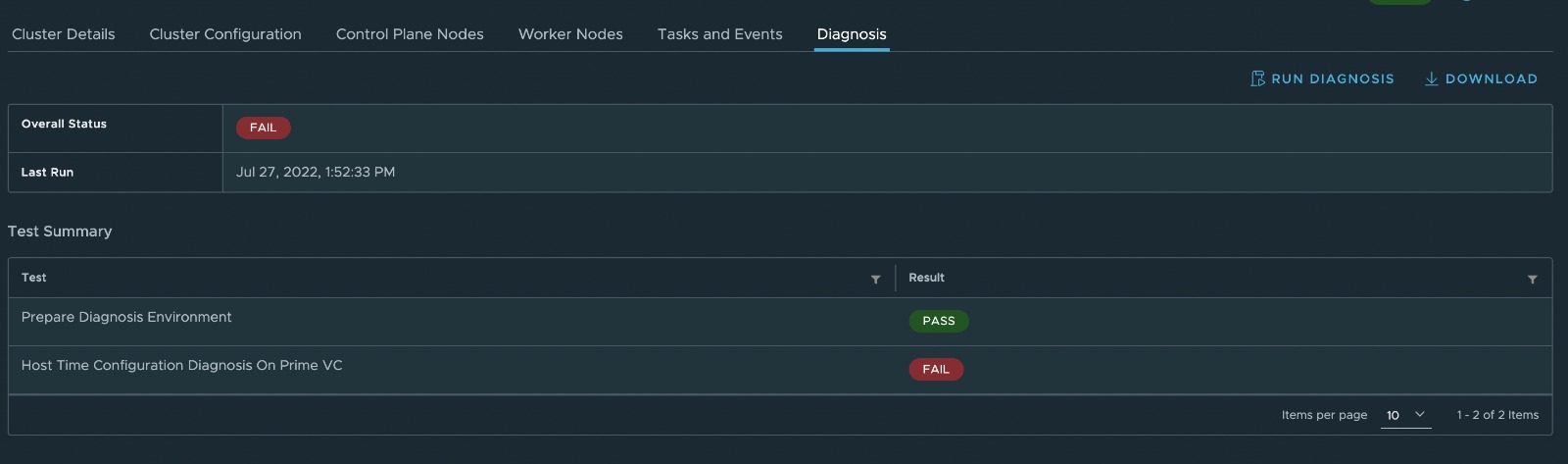
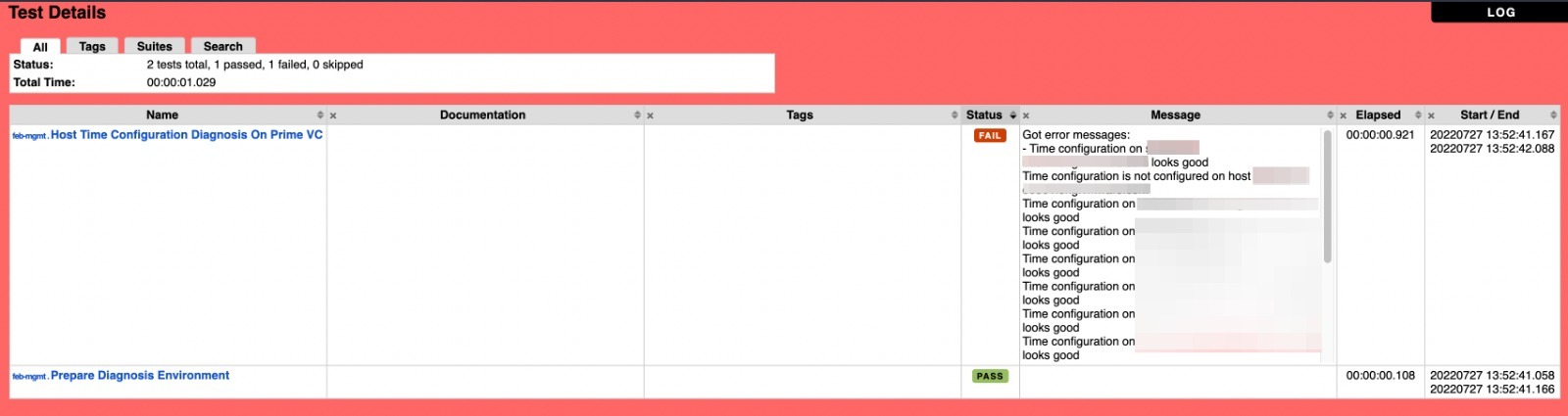
To get further insight into what made a test fail you can download the diagnosis report, which will download a tarball with a much more detailed html report, for this example one of the hosts in the cluster seems to be missing proper NTP configuration.
When run against a management cluster the following test cases will be run if the whole test suite is selected:
- Management Cluster VSphereVM Status Diagnosis
- Management Cluster Machine Status Diagnosis
- Cluster Control-Plane Nodes Diagnosis
- Cluster Worker Nodes Diagnosis
- Node IP address Diagnosis
- CAPI System Pod Diagnosis
- CAPV System Pod Diagnosis
- Cert Manager Pod Diagnosis
- VMConfig Operator Diagnosis
- NodeConfig Operator Diagnosis
- VSphere Controller Manager Diagnosis
- Etcd Pods Status Diagnosis
- Kube-apiserver Pods Status Diagnosis
- Kube-scheduler Pods Status Diagnosis
- Kube-controller-manager Pods Status Diagnosis
- Kube-proxy Pods Status Diagnosis
- CoreDNS Pods Status Diagnosis
- CNI Antrea Pods Status Diagnosis
- CSI Status Diagnosis
- Kapp-controller Pods Status Diagnosis
- Tanzu-addon-manager Pods Status Diagnosis
- Tkr Status Diagnosis
- NodeConfig certificate Diagnosis
- Host Time Configuration Diagnosis On Prime VC
- VIP address conflict detection
- Etcd Status Diagnosis
When run against a worklaod cluster the following test cases will be run if the whole test suite is selected:
- VSphereVM Status Diagnosis
- Machine Status Diagnosis
- Cluster Control-Plane Nodes Diagnosis
- Cluster Worker Nodes Diagnosis
- Node IP address Diagnosis
- VMConfig Diagnosis
- NodeConfig Operator Diagnosis
- VSphere Controller Manager Diagnosis
- Etcd Pods Status Diagnosis
- Kube-apiserver Pods Status Diagnosis
- Kube-scheduler Pods Status Diagnosis
- Kube-controller-manager Pods Status Diagnosis
- Kube-proxy Pods Status Diagnosis
- CoreDNS Pods Status Diagnosis
- CNI Status Diagnosis
- CSI Status Diagnosis
- Kapp-controller Pods Status Diagnosis
- NodeConfig certificate Diagnosis
- VIP address conflict detection
- Etcd Status Diagnosis
- NodePolicy Diagnosis
- NodePolicyMachineStatus Diagnosis
- NodeProfileStatus Diagnosis
Overall this for me is one of the best features which Telco Cloud Automation added. It's an extremely common ask to be able to perform a general health check on a cluster, especially prior to performing an upgrade, or validating the functional status after an onboarding or upgrade operation. Also having dealt with a high scale RAN deployment the last couple of weeks, simply being able to check the health of a cluster within a few seconds before diving deeper into troubleshooting something is an amazing time saver, as usually it's very simple things being broken.